Homemade caching with Laravel

Welcome to the first part of our two-piece blog story where we dive into the implementation of a database-based caching facility using Laravel. In this first part, we’ll explore why caching is crucial, our decision to go with homemade caching, and the core elements of our caching system.
Salient points:
- why caching in the first place, and why responses?
- existing libraries and why we did not use them
- main abstraction: the response generator closure
Why caching?

Caching is a vital aspect of web applications, primarily designed to boost performance. It helps eliminate the pain of slow responses and it is particularly effective for websites that are mostly read-heavy. However, for interactive Software as a Service (SaaS) solutions like ours, the challenge lies in managing cache invalidation. Stale information must be avoided to ensure data accuracy.
Existing Libraries: Why We Chose Homemade Caching
When considering caching solutions, we explored two main options.
Option #1: existing libraries
We initially looked into libraries like Spatie’s laravel-responsecache. While it’s an excellent choice for caching GET requests, it didn’t align with our specific requirements. We needed more control and flexibility over the caching mechanism, especially for non-GET requests. Our opinion:
- this library is a very good solution for blanket caching on GETs, which is the typical use case for catalogues
- they provide very good abstractions, like a hasher, but their implementation is really meant for GETs (e.g. they don’t hash query parameters)
- introducing it to still use very little of that (like the base classes and the e-tag headers) didn’t feel like a good deal
So we went to homemade caching, and In this blog, we’ll provide a detailed insight into our homemade caching system.
Option #2: homemade caching
To meet our peculiar caching needs, we opted for a custom solution. Our homemade caching approach leverages Laravel’s caching abstractions, uses the database as the cache store, and implements a custom tagging mechanism to manage cached data effectively.
Homemade Caching
Homemade caching has three main ingredients:
- rely as much as possible on the existing Cache abstractions by Laravel
- use our database as cache (
DatabaseStoretrait) so that we won't add any complexity in our architecure (e.g. Redis and stuff) - a tagging (keying, partitioning) mechanism: be able to reap and flush all keys in a group
Say that we will show more of this later, detailing our implementation.
Closures
Closures are a powerful and essential, and they play a crucial role in making your code more maintainable, reusable, and efficient. Closures are anonymous functions that can capture variables from their surrounding scope, allowing you to create self-contained units of code that can be passed around like regular values.
Closures play very important role in our homemade caching feature. Since we were not totally confident about putting “everything” into a closure, this feature was rolled out behind a feature flag. To make use of them though, we had to make sure that each controller method stayed very clean, with well-separated logic in order to keep it consistency: for example, we adopted strict typing to avoid nasty surprises when filling in theself::generateResponse method. This method, as we will see better in the technical section below, expects three parameters:
- key: the key for the cache entry
- closure: the function to produce the value to be cached
- refresh flag: whether to ignore the cache and refresh the entry
Here is one of example, where our main self::generateResponse method accepts three parameters:
{
$refreshCache = false ;
$key = self::getCacheKeyFormodel($model, $request);
$responseGenerator = function() use ($model) {
// core logic here
return response()->json(new ModelResource($model), 200);
};
return self::generateResponse(
$key, // key for cache
$responseGenerator, // logic to run
$refresh // re-write new response
);
}Note that in theory, there isn’t a substantial difference between placing the generation code within a closure as opposed to a method. Utilizing a closure offers the advantage of a cleaner abstraction, as it provides the caching manager with a more concise package, eliminating the need to introduce an array of methods at each endpoint we utilize.
A word of attention
As already mentioned, we were a little careful though: closures (callables, lambdas etc) are not exactly first-class citizens in most programming languages, and things like memory footprints and internal serializations do play a role.
Including numerous arguments within a use-statement effectively entails encapsulating a considerable amount of state. This results in a substantial closure objects that accompany the code. Such heavy objects can impact garbage collection efficiency and potentially lead to issues when attempting to serialize and transport these closures. It’s worth noting that one should refrain from closing over dynamic content, such as referencing a class instance in your use statement.
Core implementation
Let’s go through our core trait for this feature which is ManageWebCache and we will see how each method is working and why we have used certain approaches, code is written is modular way that each function contain it's related logic and can be used anywhere else.
Main flow: when users hit an endpoint, a controller method ModelController@get is going call a private lookup method which will call the ManageWebCache trait method self::generateResponse , all very clean; and that ManageWebCache@generateResponse method is going to check if feature is enabled to generate a response and possibly refresh the cache.
Step 1 — Cache Configuration
The cache is meticulously configured in our config/cache.php file, with its characteristics carefully defined. Utilizing a database-driven approach, we have the database cache driver. The cache_responses table serves as the repository for our cached responses, ensuring their persistence and quick retrieval. To maintain coherence with our application's architecture and prevent any conflicts, we diligently set the connection to align with our default database configuration.
<?php
use Illuminate\Support\Str;
return[
'stores' => [
'responses' => [
'driver' => 'database',
'table' => 'cache_responses',
'connection' => config('database.default'),
],
],
'cache_enabled' => env('RESPONSE_CACHE_ENABLED', false);
'prefix' => env('CACHE_PREFIX', Str::slug(env('APP_NAME', 'laravel'), '_').'_cache'),
];Moreover, we take particular care with the cache prefix, which allows us to distinguish our cache items.
And this brings us to a few very technical points about the caches and databases.
Caches & databases
First of all, Laravel has quite simple yet well-defined base contracts for caches, the Store trait. A method which we considered essential, in order to mass-invalidate the whole line of cached items under the diamond data model entity (the company, in our case), was a forgetByPrefix() method — too bad such a method doesn’t exist.
An alternative could have been tags, but they were only supported by Memcached or Redis: we had already gotten rid of the former and didn’t want his friend to join us either, in order to keep the complexity low.
This came at the price of implementing a simple tagging mechanism ourselves, based on a simple prefixes grammar, and that allowed us clear everything for a user like this:
protected static function clearAllForUser(string $userId = null): void
{
$userIdOrDefault = $userId ?? self::getUserId();
$prefix = self::getCacheKeyPrefixForUser($userIdOrDefault);
$allUserKeys = self::getAllKeysContaining($prefix);
$missingKeys = 0;
$count = count($allUserKeys);
foreach ($allUserKeys as $userKey) {
//left-trim, because the prefix is appended by the database store calls...
$userKeyWithoutPrefix = ltrim($userKey, config(self::$cachePrefixConfigKey));
//in case we get tricked by prefixes and stuff...
self::getCache()->has($userKeyWithoutPrefix) ? $missingKeys : $missingKeys++;
self::getCache()->forget($userKeyWithoutPrefix);
}
}Step 2 — Define Trait ManageWebCache
Trait has following static private properties which contains path to our config/cache.php file:
trait ManageWebCache {
private static $driverConfigKey = 'cache.stores.responses.driver';
private static $storeNameConfigKey = 'cache.stores.responses.table';
private static $cachePrefixConfigKey = 'cache.prefix';
// [...]
}A second technical remark
If you are still wondering why we chose a file- or database-backed store, some more detail is welcome.
Caching in a database (in our case an external system, albeit with high vicinity) is not great for latency. On the other hand, in our Azure AppService-based node, file-based would’ve entailed multiple caches.
At least in our case, the time saved on skipping the calculation altogether definitely beat the added latency to fetch the cache keys.
Step 3 — Generate key
An incoming request is always associated to a platform user — in particular, it can always be associated to the main resource in our domain — but it does not have to necessarily come from that specific authenticated user: the request may originate from another user in the same team, or from the system itself.
To generate a key for model we have a method in trait ManageWebCache@getCacheKeyForModel which will generatethe key for each incoming request; the key is a string combination of the company id (“company” is our main domain resource) and the request payload hash:
protected static function getCacheKeyForModel(Model $model, Request $request): string
{
$prefix = self::getCacheKeyPrefixForModel($model);
$requestHash = self::getHashFor($request);
return "$prefix-request-$requestHash"; // cache key
}To generate the prefix of key, luckily in our business domain model, everything always belongs to a company eventually, it is the top-level resource. So, indexing by company identifier is not only handy for prefix-based invalidation, but also to make the caching scope private to the company itself. Same concept for users as well: if we would like to clear all models for specific user we can do so by relying on the getCacheKeyPrefixForUser() method:
private static function getCacheKeyPrefixFormodel(Model $model): string
{
$companyId = $model->company_id;
return "@company:" . $companyId . '@';
}
private static function getCacheKeyPrefixForUser(string $userId): string
{
$companyId = self::getCompanyId($userId);
return "@company:" . $companyId . '@';
}
private static function getCompanyId(string $userId): string
{
$user = User::find($userId);
$companyId = $user ? ($user->getCompanyIdAttribute() ?? 'none') : 'none';
return $companyId;
}As you have already noticed, we keep a server log for every critical step, so having a right key is very important to able to identify which keys belong to which route and method.
To make it unique but handy we’re helped by a classic MD5 hashing. We hash the body content and params too, because we are working with POST requests too.
The reader might argue that POST requests are not to be cached, because they create resources in the application, in classic rest terms; the thing is that we use this verb to drive expensive calculations too, where the parameters are posted in the request body; therefore, the request path and query parameters are not enough (again one of the reasons why we didn’t use the Spatie library).
private static function getHashFor(Request $request): string
{
$requestUrl = self::getNormalizedRequestUrl($request);
$method = $request->getMethod();
$content = $request->getContent();
$parametersString = serialize($content);
Log::debug("
=== Incoming cacheable request === \n
Request URL: $requestUrl \n
Method: $method \n
Content: $content \n
====== \n
");
return "responsecache-requesturl:$requestUrl-method:$method-" . md5("{$requestUrl}-{$method}-{$parametersString}");
}getNormalizedRequestUrl method is simple which gives url related content, if there is any query specially for a GET request we can append the string starting from ?and The URL should contain an id reference to the resource, e.g. /some/path/model/42 for model 42 :
private static function getNormalizedRequestUrl(Request $request): string
{
if ($queryString = $request->getQueryString()) {
$queryString = '?' . $queryString;
}
return $request->getBaseUrl() . $request->getPathInfo() . $queryString;
}Step 4 — Generate Response & Set Cache
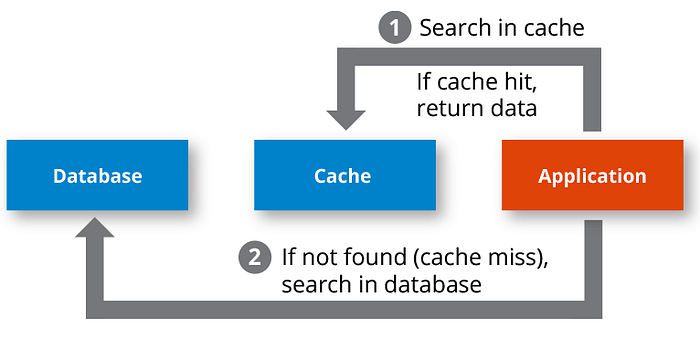
After getting the correct key for our cache, the next step is to pass all data to thegenerateResponse method which is the main core method to handle all cache related logic and every controller will be using this method in order to implement cache.
generateResponse checks if a response is available in the cache and, if not, generates the response, compresses it, and stores it in the cache. It also handles exceptions and logs various messages to track cache hits, misses, and errors. The final response is returned to the caller.
protected static function generateResponse(string $key, callable $generator, bool $refresh = false)
{
$response = null;
try {
if (config('cache.cache_enabled')) { // check if feature is enabled - default false from config file
if (!$refresh && self::getCache()->has($key)) { // return from cache
Log::info("Responses cache hit for response with key '$key'");
$responseCompressed = self::getCache()->get($key);
$responseUncompressed = gzuncompress($responseCompressed);
$response = response()->json(json_decode($responseUncompressed));
} elseif ($refresh) {
Log::info("Refreshing entry for response with key '$key'");
} else {
Log::info("Responses cache miss for response with key '$key'");
}
if (!$response) { // re-generate and set cache
$response = $generator();
$responseString = $response->getContent();
$responseCompressed = gzcompress($responseString);
if (!self::getCache()->put($key, $responseCompressed, new \DateTime('tomorrow 11:59 PM'))) {
Log::error("Cache refuses to cache key with value $key");
}
}
} else {
$response = $generator();
Log::info("Responses caching disabled");
}
} catch (\Throwable $t) {
$message = $t->getMessage();
Log::error("Error while hitting the cache: $message");
$response = $generator();
}
return $response;
}Method Signature
As we mentioned above, this method takes three parameters:
$key(string): A unique identifier for the cached response.$generator(callable): A function that generates the response if it's not found in the cache.$refresh(bool, optional): A flag to force a refresh of the cache.
Caching Logic
The code checks if caching is enabled based on the value of config('cacheable.cache_enabled'). If caching is enabled, it proceeds to check if the response is already in the cache ( self::getCache()->has($key)), so that we have the following cases:
- If the response is found in the cache and
$refreshis not true, it retrieves the cached response, decompresses it, and returns it. - If
$refreshis true, it logs that the entry is being refreshed. - If the response is not in the cache or if caching is disabled, it logs a cache miss.
Generating and Caching
If the response is not in the cache, or if caching is disabled, it generates the response by calling the$generator function. It then compresses the response using gzcompress and stores it in the cache using $key. The cache entry is set to expire at a specific time in the future (tomorrow at 11:59 PM)
Exception Handling
The code includes exception handling. If an error occurs during the caching or response generation process, it catches the exception, logs an error message, and generates a response using the$generator function.
Return Value
The method returns the generated response. If caching is enabled and a cached response is available, it returns the cached response. Otherwise, it returns the newly generated response.
More technicalities
There’s a number of pretty cool facts we are not breaking down here, for the sake of readibility:
- how to construct a safe prefix grammar for your tags
- thread safety of the cache traits: it depends on the cache flavor
- what to put and not to put in the cache key
Should you be interested, don’t hesitate to ask!
See you on next hit, do not miss!
In the second part of the blog, we will focus on the other half of the cache management: when to clear entries, or invalidate the cache altogether? See you then!
Blog by Riccardo Vincelli and Usama Liaquat brought to you by the engineering team at Sharesquare.